

Near-field Source Extraction Using Speech Presence Probabilities for Ad hoc Microphone Arrays
Maja Taseska, Shmulik Markovich Golan, Emanuël A. P. Habets and Sharon Gannot
Published in the Proc. of the International Workshop on Acoustic Signal Enhancement, Antibes Juan les Pins, French Riviera 2014.
Abstract
Ad hoc wireless acoustic sensor networks (WASN) hold great potential for improved performance in speech processing applications, thanks to better coverage and higher diversity of the received signals. We consider a multiple speaker scenario where each of the WASN nodes, an autonomous system comprising of sensing, processing and communicating capabilities, is positioned in the near-field of one of the speakers. Each node aims at extracting its nearest speaker while suppressing other speakers and noise. The ad hoc network is characterized by an arbitrary number of speakers/nodes with uncontrolled microphone constellation. In this paper we propose a distributed algorithm which shares information between nodes. The algorithm requires each node to transmit a single audio channel in addition to a soft time-frequency (TF) activity mask for its nearest speaker. The TF activity masks are computed as a combination of estimates of a model-based speech presence probability (SPP), direct-to-diffuse ratio (DDR) and direction-of-arrival (DOA) per TF bin. The proposed algorithm, although sub-optimal compared to the centralised solution, is superior to the single-node solution.
Description
The sound examples are obtained using recorded data in a room with dimensions 4.5 m x 4.5 m x 3 m. Three uniform circular arrays were used with diameter 2.9 cm and with three microphones each. The reverberation time of the room was approximately 170 ms. Background noise was generated by emitting uncorrelated babble speech signals from 9 loudspeakers placed near the walls of the room, facing away from the microphone arrays.
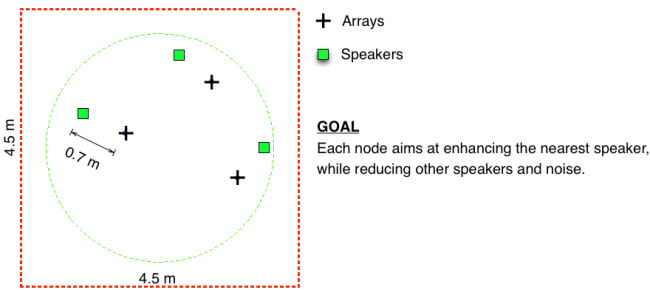
Audio Examples
Three speakers plus white sensor noise. Results at Node 1 during triple talk.
Three speakers plus white sensor noise. Results at Node 2 during triple talk.
Three speakers plus white sensor noise. Results at Node 3 during triple talk.
Three speakers plus diffuse babble speech. Results at Node 1 during triple talk.
Three speakers plus diffuse babble speech. Results at Node 2 during triple talk.
Three speakers plus diffuse babble speech. Results at Node 3 during triple talk.