

Demos and Code
Evaluating Speech—Phoneme Alignment and Its Impact on Neural Text-To-Speech Synthesis

Link: Website
In recent years, the quality of text-to-speech (TTS) synthesis vastly improved due to deep-learning techniques, with parallel architectures, in particular, providing excellent synthesis quality at fast inference. Training these models usually requires speech recordings, corresponding phoneme-level transcripts, and the temporal alignment of each phoneme to the utterances. Since manually creating such fine-grained alignments requires expert knowledge and is time-consuming, it is common practice to estimate them using automatic speech–phoneme alignment methods. In the literature, either the estimation methods' accuracy or their impact on the TTS system's synthesis quality is evaluated. In this study, we perform experiments with five state-of-the-art speech–phoneme aligners and evaluate their output with objective and subjective measures. As our main result, we show that small alignment errors (below 75 ms error) do not decrease the synthesis quality, which implies that the alignment error may not be the crucial factor when choosing an aligner for TTS training.
CTC-Based Learning of Chroma Features for Score—Audio Music Retrieval

Link: Website
This paper deals with a score–audio music retrieval task where the aim is to find relevant audio recordings of Western classical music, given a short monophonic musical theme in symbolic notation as a query. Strategies for comparing score and audio data are often based on a common mid-level representation, such as chroma features, which capture melodic and harmonic properties. Recent studies demonstrated the effectiveness of deep neural networks that learn task-specific mid-level representations. Usually, such supervised learning approaches require score–audio pairs where individual note events of the score are aligned to the corresponding time positions of the audio excerpt. However, in practice, it is tedious to generate such strongly aligned training pairs. As one contribution of this paper, we show how to apply the Connectionist Temporal Classification (CTC) loss in the training procedure, which only uses weakly aligned training pairs. In such a pair, only the time positions of the beginning and end of a theme occurrence are annotated in an audio recording, rather than requiring local alignment annotations. We evaluate the resulting features in our theme retrieval scenario and show that they improve the state of the art for this task. As a main result, we demonstrate that with the CTC-based training procedure using weakly annotated data, we can achieve results almost as good as with strongly annotated data. Furthermore, we assess our chroma features in depth by inspecting their temporal smoothness or granularity as an important property and by analyzing the impact of different degrees of musical complexity on the features.
Efficient Retrieval of Music Recordings Using Graph-Based Index Structures

Link: Website
Flexible retrieval systems are required for conveniently browsing through large music collections. In a particular content-based music retrieval scenario, the user provides a query audio snippet, and the retrieval system returns music recordings from the collection that are similar to the query. In this scenario, a fast response from the system is essential for a positive user experience. For realizing low response times, one requires index structures that facilitate efficient search operations. One such index structure is the K-d tree, which has already been used in music retrieval systems. As an alternative, we propose to use a modern graph-based index, denoted as Hierarchical Navigable Small World (HNSW) graph. As our main contribution, we explore its potential in the context of a cross-version music retrieval application. In particular, we report on systematic experiments comparing graph- and tree-based index structures in terms of the retrieval quality, disk space requirements, and runtimes. Despite the fact that the HNSW index provides only an approximate solution to the nearest neighbor search problem, we demonstrate that it has almost no negative impact on the retrieval quality in our application. As our main result, we show that the HNSW-based retrieval is several orders of magnitude faster. Furthermore, the graph structure also works well with high-dimensional index items, unlike the tree-based structure. Given these merits, we highlight the practical relevance of the HNSW graph for music information retrieval (MIR) applications.
MTD: A Multimodal Dataset of Musical Themes for MIR Research

Link: Website
Musical themes are essential elements in Western classical music. In this paper, we present the Musical Theme Dataset (MTD), a multimodal dataset inspired by “A Dictionary of Musical Themes” by Barlow and Morgenstern from 1948. For a subset of 2067 themes of the printed book, we created several digital representations of the musical themes. Beyond graphical sheet music, we provide symbolic music encodings, audio snippets of music recordings, alignments between the symbolic and audio representations, as well as detailed metadata on the composer, work, recording, and musical characteristics of the themes. In addition to the data, we also make several parsers and web-based interfaces available to access and explore the different modalities and their relations through visualizations and sonifications. These interfaces also include computational tools, bridging the gap between the original dictionary and music information retrieval (MIR) research. The dataset is of relevance for various subfields and tasks in MIR, such as cross-modal music retrieval, music alignment, optical music recognition, music transcription, and computational musicology.
Using Weakly Aligned Score—Audio Pairs to Train Deep Chroma Models for Cross-Modal Music Retrieval

Link: Website
Many music information retrieval tasks involve the comparison of a symbolic score representation with an audio recording. A typical strategy is to compare score–audio pairs based on a common mid-level representation, such as chroma features. Several recent studies demonstrated the effectiveness of deep learning models that learn task-specific mid-level representations from temporally aligned training pairs. However, in practice, there is often a lack of strongly aligned training data, in particular for real-world scenarios. In our study, we use weakly aligned score–audio pairs for training, where only the beginning and end of a score excerpt is annotated in an audio recording, without aligned correspondences in between. To exploit such weakly aligned data, we employ the Connectionist Temporal Classification (CTC) loss to train a deep learning model for computing an enhanced chroma representation. We then apply this model to a cross-modal retrieval task, where we aim at finding relevant audio recordings of Western classical music, given a short monophonic musical theme in symbolic notation as a query. We present systematic experiments that show the effectiveness of the CTC-based model for this theme-based retrieval task.
Tools for Semi-Automatic Bounding Box Annotation of Musical Measures in Sheet Music
Link: Website
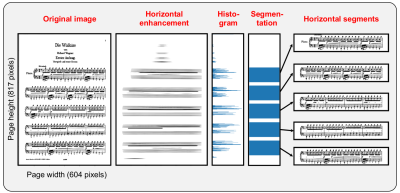
In score following, one main goal is to highlight measure positions in sheet music synchronously to audio playback. Such applications require alignments between sheet music and audio representations. Often, such alignments can be computed automatically in the case that the sheet music representations are given in some symbolically encoded music format. However, sheet music is often available only in the form of digitized scans. In this case, the automated computation of accurate alignments poses still many challenges. In this contribution, we present various semi-automatic tools for solving the subtask of determining bounding boxes (given in pixels) of measure positions in digital scans of sheet music—a task that is extremely tedious when being done manually.
Evaluating Salience Representations for Cross-Modal Retrieval of Western Classical Music Recordings
Link: Website
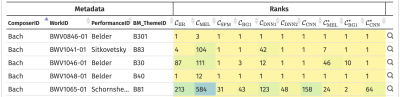
In this paper, we consider a cross-modal retrieval scenario of Western classical music. Given a short monophonic musical theme in symbolic notation as query, the objective is to find relevant audio recordings in a database. A major challenge of this retrieval task is the possible difference in the degree of polyphony between the monophonic query and the music recordings. Previous studies for popular music addressed this issue by performing the cross-modal comparison based on predominant melodies extracted from the recordings. For Western classical music, however, this approach is problematic since the underlying assumption of a single predominant melody is often violated. Instead of extracting the melody explicitly, another strategy is to perform the cross-modal comparison directly on the basis of melody-enhanced salience representations. As the main contribution of this paper, we evaluate several conceptually different salience representations for our cross-modal retrieval scenario. Our extensive experimental results, which have been made available on a website, comprise more than 2000 musical themes and 100 hours of audio recordings.
A Web-Based Interface for Score Following and Track Switching in Choral Music
Link: Website
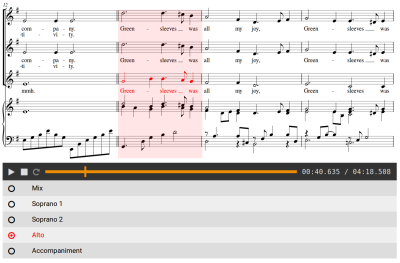
Music can be represented in many different ways. In particular, audio and sheet music renditions are of high importance in Western classical music. For choral music, a sheet music representation typically consists of several parts (for the individual singing voice sections) and possibly an accompaniment. Within a choir rehearsal scenario, there are various tasks that can be supported by techniques developed in music information retrieval (MIR). For example, it may be helpful for a singer if both, audio and sheet music modalities, are present synchronously—a well-known task that is known as score following. Furthermore, listening to individual parts of choral music can be very instructive for practicing. The listening experience can be enhanced by switching between the audio tracks of a suitable multi-track recording. In this contribution, we introduce a web-based interface that integrates score-following and track-switching functionalities, build upon already existing web technology.