

Research Highlights Archive
A Novel Frequency Domain Prediction Method for Low Delay General Audio Coding

Research on audio signal analysis exploits the signal characteristics, utilizes the knowledge of psychoacoustics based on the human auditory system, and aims to discover more potential of what can be achieved with audio processing, and thus continues to challenge the boundary of state-of-art audio coding technologies.
In a recently published journal article, joint expertise in various fields of audio signal analysis leads to the proposal of a novel long-term prediction (LTP) method for low delay transform domain general audio coders.
This frequency domain joint harmonics prediction (FDJHP) method provides transform based general audio codecs with an LTP tool to reduce the redundancy which exists in periodic or quasi-periodic audio signal components. Those components occur e.g. in music containing dominant single instrument signals and in voiced speech. The FDJHP method enables joint prediction of harmonic components, even if they heavily overlap in their influence on their spectral representation. That overlap is usually observed in low delay audio coding scenarios, where coding delays are required to be as low as a few milliseconds.
Performance analysis using bitrate savings and a listening test using test signals with strong harmonic components indicate that FDJHP can improve the coding efficiency greatly. Further experiments show that FDJHP can be combined with existing techniques into an adaptive system, where different prediction methods can complement each other.
Read the article at IEEE. Learn more about the research field Audio Signal Analysis.
Interactive Learning of Signal Processing Through Music
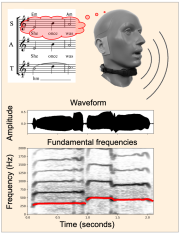 Digital music has become a ubiquitous and vital part of our lives. Conversely, as a scientific discipline, digital signal processing can be obtuse and unfamiliar to newcomers. Conceptual and practical understanding of signal processing requires a rather sophisticated knowledge of advanced mathematics. In a new IEEE article, Meinard Müller et al. show how music may serve as a vehicle to make learning signal processing an interactive pursuit.
Digital music has become a ubiquitous and vital part of our lives. Conversely, as a scientific discipline, digital signal processing can be obtuse and unfamiliar to newcomers. Conceptual and practical understanding of signal processing requires a rather sophisticated knowledge of advanced mathematics. In a new IEEE article, Meinard Müller et al. show how music may serve as a vehicle to make learning signal processing an interactive pursuit.
Read the article at IEEE. A preprint version can be found here.
Learn more about the research field Music Processing.
HRTF measurements for binaural sound research
 Head Related Transfer Functions (HRTFs) are essential to research in the field of binaural sound reproduction. HRTFs can be obtained from existing databases, but there are also a few rare facilities around the world where you can get your very own HRTFs measured. This is what a group of scientists from AudioLabs and Fraunhofer IIS ventured out to do last week.
Head Related Transfer Functions (HRTFs) are essential to research in the field of binaural sound reproduction. HRTFs can be obtained from existing databases, but there are also a few rare facilities around the world where you can get your very own HRTFs measured. This is what a group of scientists from AudioLabs and Fraunhofer IIS ventured out to do last week.
Score-informed Music Separation and Restoration applied to Drum Recordings
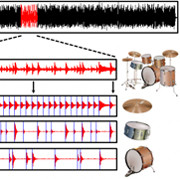 This research investigates the suitability of Non-Negative Matrix Factor Deconvolution (NMFD) for source separation of drum solo
recordings (especially breakbeats) into their constituent drum sound events. Intuitively speaking, NMFD models the drum recording with a
small number of template sound events, ideally corresponding to the sound of individual drum instruments. The accompanying website lists
several audio examples of decompositions of iconic breakbeats as well as selected items from the "IDMT-SMT-Drums" test set.
This research has also been presented in a talk on "breakbeat science" given by Jason Hockman at the Ableton Loop conference
(see the video).
Visit the Website for more information and audio examples!
This research investigates the suitability of Non-Negative Matrix Factor Deconvolution (NMFD) for source separation of drum solo
recordings (especially breakbeats) into their constituent drum sound events. Intuitively speaking, NMFD models the drum recording with a
small number of template sound events, ideally corresponding to the sound of individual drum instruments. The accompanying website lists
several audio examples of decompositions of iconic breakbeats as well as selected items from the "IDMT-SMT-Drums" test set.
This research has also been presented in a talk on "breakbeat science" given by Jason Hockman at the Ableton Loop conference
(see the video).
Visit the Website for more information and audio examples!
Intelligibility Evaluation of Speech Coding Standards
 Speech intelligibility is an important aspect of speech
transmission but often when speech coding standards are compared only the quality is evaluated using perceptual tests.
In this study, the performance of three wideband speech coding standards, adaptive multi-rate wideband (AMR-WB), G.718,
and enhanced voice services (EVS), is evaluated in a subjective intelligibility test. The test covers different packet loss conditions
as well as a near-end background noise condition. Additionally, an objective quality evaluation in different packet loss conditions is conducted.
All of the test conditions extend beyond the specification range to evaluate the attainable performance of the codecs in extreme conditions.
The results of the subjective tests show that both EVS and G.718 are better in terms of intelligibility than AMR-WB. EVS attains
the same performance as G.718 with lower algorithmic delay.
Speech intelligibility is an important aspect of speech
transmission but often when speech coding standards are compared only the quality is evaluated using perceptual tests.
In this study, the performance of three wideband speech coding standards, adaptive multi-rate wideband (AMR-WB), G.718,
and enhanced voice services (EVS), is evaluated in a subjective intelligibility test. The test covers different packet loss conditions
as well as a near-end background noise condition. Additionally, an objective quality evaluation in different packet loss conditions is conducted.
All of the test conditions extend beyond the specification range to evaluate the attainable performance of the codecs in extreme conditions.
The results of the subjective tests show that both EVS and G.718 are better in terms of intelligibility than AMR-WB. EVS attains
the same performance as G.718 with lower algorithmic delay.
Score-Informed Source Separation
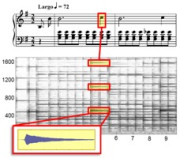 One central problem in music signal processing is the decomposition of a given audio recording of
polyphonic music into sound components that correspond to musical voices, instrument tracks,
or individual note events. One main challenge arises from the fact that musical sources are highly correlated,
share the same harmonies and follow the same rhythmic patterns. In current research, we use additional cues
such as the musical score to support the separation process. The score also provides a natural way
for a user to interact with the separated sound events.
One central problem in music signal processing is the decomposition of a given audio recording of
polyphonic music into sound components that correspond to musical voices, instrument tracks,
or individual note events. One main challenge arises from the fact that musical sources are highly correlated,
share the same harmonies and follow the same rhythmic patterns. In current research, we use additional cues
such as the musical score to support the separation process. The score also provides a natural way
for a user to interact with the separated sound events.